4. Search-Friendly Site Navigation
Site navigation is something that web designers have been putting
considerable thought and effort into since websites came into existence.
Even before search engines were significant, navigation played an
important role in helping users find what they wanted. It plays an
important role in helping search engines understand your site as
well.
4.1. Basics of search engine friendliness
The search engine spiders need to be able to read and interpret
your website’s code to properly spider and index the content on your
web pages. Do not confuse this with the rules of organizations such as
the W3C, which issues guidelines on HTML construction. Although
following the W3C guidelines can be a good idea, the great majority of
sites do not follow these guidelines, so search engines generally
overlook violations of these rules as long as their spiders can parse
the code.
Unfortunately, there are also a number of ways that navigation
and content can be rendered on web pages that function for humans, but
are invisible (or challenging) for search engine spiders.
For example, there are numerous ways to incorporate content and
navigation on the pages of a website. For the most part, all of these
are designed for humans. Basic HTML text and HTML links such as those
shown in Figure 10
work equally well for humans and search engine crawlers.

The text and the link that are indicated on the page shown in
Figure 6-12 (the
Alchemist Media home page) are in simple HTML format.
4.2. Site elements that are problematic for spiders
However, many other types of content may appear on a web page
and may work well for humans but not so well for search engines. Here
are some of the most common ones.
4.3. Search and web forms
Many sites incorporate search functionality. These “site search”
elements are specialized search engines that index and provide access
to one site’s content.
This is a popular method of helping users rapidly find their way
around complex sites. For example, the Pew Internet website provides
Site Search in the top-right corner; this is a great tool for users,
but search engines will be stymied by it. Search engines operate by
crawling the Web’s link structure—they don’t submit forms or attempt
random queries into search fields, and thus, any URLs or content
solely accessible via a “site search” function will remain invisible
to Google, Yahoo!, and Bing.
Forms are a popular way to provide interactivity, and one of the
simplest applications is the “contact us” form many websites
have.
Unfortunately, crawlers will not fill out or submit forms such
as these; thus, any content restricted to those who employ them is
inaccessible to the engines. In the case of a “contact us” form, this
is likely to have little impact, but other types of forms can lead to
bigger problems.
Websites that have content behind logins will either need to
provide text links to the content behind the login (which defeats the
purpose of the login) or implement First Click Free.
4.3.1. Java, images, audio, and video
Adobe Shockwave files, Java embeds, audio, and video (in any
format) present content that is largely uncrawlable by the major
engines. With some notable exceptions that we will discuss later,
search engines can read text only when it is presented in HTML
format. Embedding important keywords or entire paragraphs in an
image or a Java console renders them invisible to the spiders.
Likewise, words spoken in an audio file or video cannot be read by
the search engines.
Alt attributes, originally
created as metadata for markup and an accessibility tag for
vision-impaired users, is a good way to present at least some text
content to the engines when displaying images or embedded, nontext
content. Note that the alt
attribute is not a strong signal, and using the alt attribute on an image link is no
substitute for implementing a simple text link with targeted anchor
text. A good alternative is to employ captions and text descriptions
in the HTML content wherever possible.
In the past few years, a number of companies offering
transcription services have cropped up, providing automated text
creation for the words spoken in audio or video. Providing these
transcripts on rich media pages makes your content accessible to the
search engines and findable by keyword-searching visitors. You can
also use software such as Dragon Naturally Speaking and dictate your
“transcript” to your computer.
4.3.2. AJAX and JavaScript
JavaScript enables many dynamic functions inside a website,
most of which interfere very minimally with the operations of a
search engine spider. The exception comes when a page must use a
JavaScript call to reach another page, or to pull content that the
spiders can’t see in the HTML. Though these instances are relatively
rare, it pays to be aware of how the robots spider and index—both
content and links need to be accessible in the raw HTML of a page to
avoid problems.
Asynchronous JavaScript and XML (AJAX) presents similar
problems, most notably in the delivery of content that search
engines cannot spider. Since AJAX uses database calls to retrieve
data without refreshing a page or changing URLs, the content
contained behind these technologies is frequently completely hidden
from the search engines (see Figure 11).
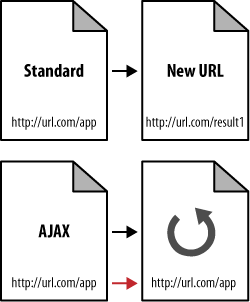
When AJAX is used you may want to consider implementing an
alternative spidering system for search engines to follow. AJAX
applications are so user-friendly and appealing that for many
publishers foregoing them is simply impractical. Building out a
directory of links and pages that the engines can follow is a far
better solution.
When you build these secondary structures of links and pages,
make sure to provide users with access to them as well. Inside the
AJAX application itself, give your visitors the option to “directly
link to this page” and connect that URL with the URL you provide to
search spiders through your link structures. AJAX apps not only
suffer from unspiderable content, but often don’t receive accurate
links from users since the URL doesn’t change.
Newer versions of AJAX use a # delimiter, which acts as a query string
into the AJAX application. This does allow you to link directly to
different pages within the application. However, the #, which is used for HTML bookmarking, and
everything past it, is ignored by search engines.
This is largely because web browsers use only what’s after the
# to jump to the anchor within
the page, and that’s done locally within the browser. In other
words, the browser doesn’t send the full URL, so the parameter
information (i.e., any text after the #) is not passed back to the
server.
So, don’t use your ability to link to different pages within
the AJAX application as a solution to the problem of exposing
multiple pages within the application to search engines. All of the
pages exposed in this way will be seen as residing on the same URL
(everything preceding the #).
Make sure you create discrete web pages that have unique URLs for
the benefit of search engines.
4.3.3. Frames
Frames emerged in the mid-1990s as a popular way to make easy
navigation systems. Unfortunately, both their usability (in 99% of
cases) and their search friendliness (in 99.99% of cases) were
exceptionally poor. Today, iframes and CSS can replace the need for
frames, even when a site’s demands call for similar
functionality.
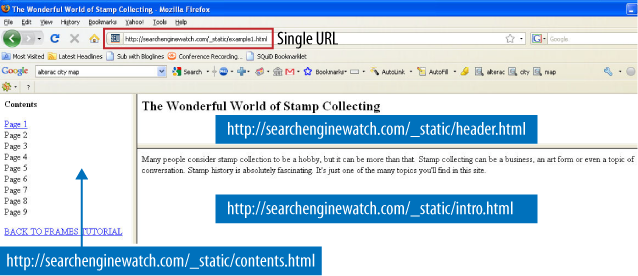
For search engines, the biggest problem with frames and
iframes is that they often hold the content from two or more URLs on
a single page. For users, search engines, which direct searchers to
only a single URL, may get confused by frames and direct visitors to
single pages (orphan pages) inside a site intended to show multiple
URLs at once.
Additionally, since search engines rely on links, and frame
pages will often change content for users without changing the URL,
external links often point to the wrong URL unintentionally. As a
consequence, links to the page containing the frame or iframe may
actually not point to the content the linker wanted to point to.
Figure 12 shows an example page
that illustrates how multiple pages are combined into a single URL
with frames, which results in link distribution and spidering
issues.
4.4. Search-engine-friendly navigation guidelines
Although search engine spiders have become more advanced over
the years, the basic premise and goals remain the same: spiders find
web pages by following links and record the content of the pages they
find in the search engine’s index (a giant repository of data about
websites and pages).
In addition to avoiding the techniques we just discussed, there
are some additional guidelines for developing search-engine-friendly
navigation:
Implement a text-link-based navigational structure
If you choose to create navigation in Flash, JavaScript,
or other technologies, make sure to offer alternative text links
in HTML for spiders to ensure that automated robots (and
visitors who may not have the required browser plug-ins) can
reach your pages.
Beware of “spider traps”
Even intelligently coded search engine spiders can get
lost in infinite loops of links that pass between pages on a
site. Intelligent architecture that avoids looping 301 or 302
server codes (or other redirection protocols) should negate this
issue, but sometimes online calendar links, infinite pagination
that loops, or massive numbers of ways in which content is
accessible or sorted can create tens of thousands of pages for
search engine spiders when you intended to have only a few dozen
true pages of content. You can read more about Google’s
viewpoint on this at http://googlewebmastercentral.blogspot.com/2008/08/to-infinity-and-beyond-no.html.
Watch out for session IDs and cookies
As we just discussed, if you limit the ability of a user
to view pages or redirect based on a cookie setting or session
ID, search engines may be unable to crawl your content. The bots
do not have cookies enabled, nor can they deal with session IDs
properly (each visit by the crawler gets a URL with a different
session ID and the search engine sees these URLs with session
IDs as different URLs). Although restricting form submissions is
fine (as search spiders can’t submit forms anyway), limiting
content access via cookies and session IDs is a bad idea. Does
Google allow you to specify parameters in URLs? Yahoo! does. You
can read more about it on seroundtable.com.
Server, hosting, and IP issues
Server issues rarely cause search engine ranking
problems—but when they do, disastrous consequences can follow.
The engines are acutely aware of common server problems, such as
downtime or overloading, and will give you the benefit of the
doubt (though this will mean your content cannot be spidered
during periods of server dysfunction).
The IP address of your host can be of concern in some instances.
IPs once belonging to sites that have spammed the search engines may
carry with them negative associations that can hinder spidering and
ranking. The engines aren’t especially picky about shared hosting
versus separate boxes, or about server platforms, but you should be
cautious and find a host you trust.
Search engines have become paranoid about the use of certain
domains, hosting problems, IP addresses, and blocks of IPs. Experience
tells them that many of these have strong correlations with spam, and
thus, removing them from the index can have great benefits for users.
As a site owner not engaging in these practices,
it pays to investigate your web host prior to getting into
trouble.